I recently inherited a new Team at work which was really just a one-man army until they brought me in to support the one-man army as his Lead Technical Program Manager. Now we are hiring additional resources and are up to seven folks.
I have been analyzing the project-related data from the work accomplished by the one-man army over the last two years.
I have been tasked by our VP with adding Standard Deviation to the report that I have developed to show what has been accomplished over the last 2.5 years and what we can accomplish with our new resources once they come up to speed.
I have not had to do Standard Deviation stuff since Statistics class back in college in the late 70’s. Never was called on to use it in 48 years of my IT career…until now. I feel like I have forgotten what little I ever knew about it!
To refresh my memory, I have read various things on the Internet about what it is and does but want to make sure I am properly interpreting what I think it says.
I have the data extracted to Microsoft Excel and I am using its Std Dev function and it gives me what looks like a reasonable answer. Std Dev is used in conjunction with the Average / Mean which I also have and what the report was originally providing.
There are 305 rows of data regarding projects since January 2020. The relevant numbers are the number of Months from beginning to end it took to complete each project. This number varies greatly depending on project complexity and delays due to dependencies on 3rd parties to do some of the work.
According to Excel my Average/Mean is 10 months and my Standard Deviation is 7.5 months.
My Range of values is from .1 month to 25.1 months.
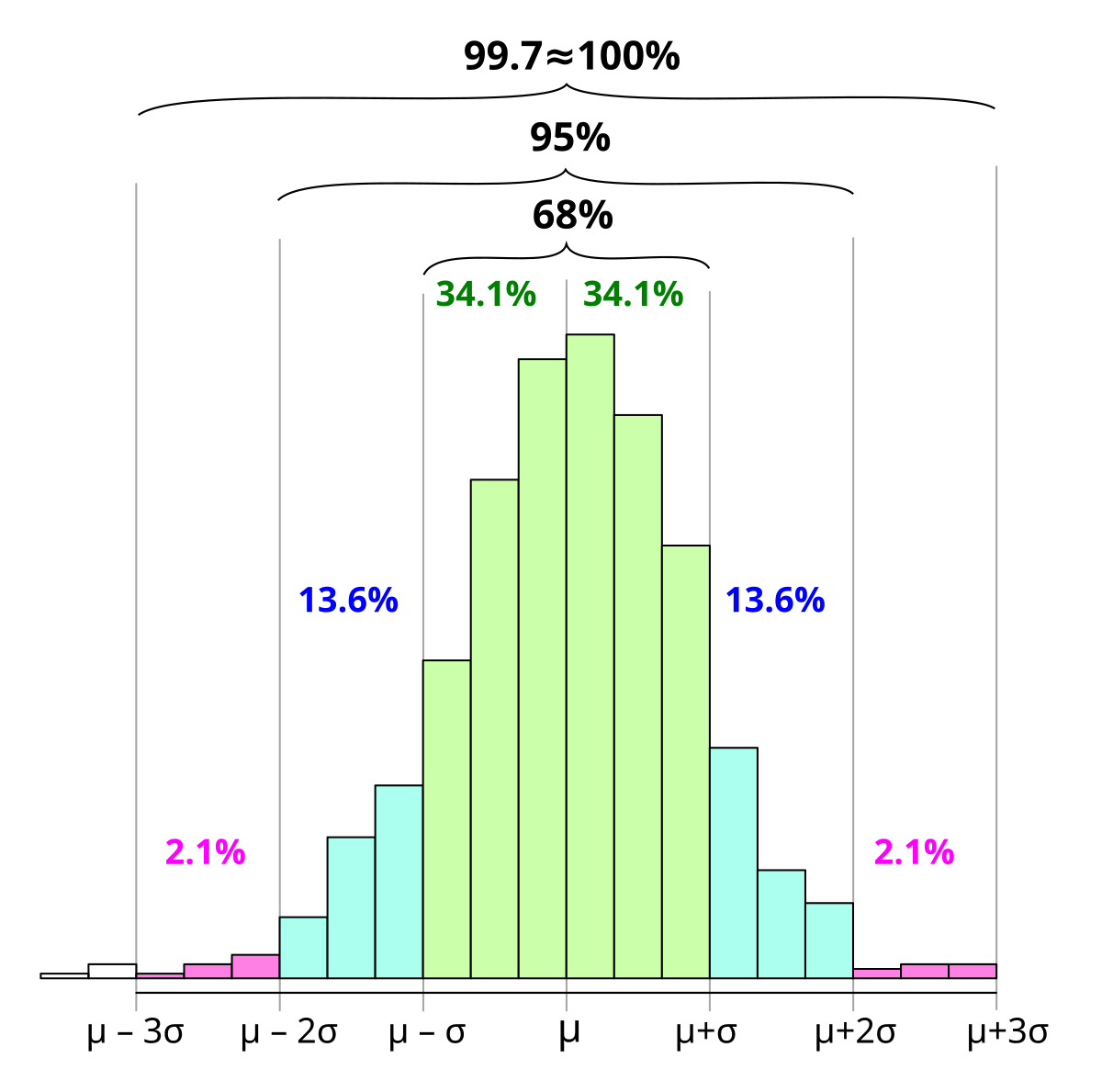
So based on the 68-95-99.7 rule for 1, 2 and 3 standard deviations, does this mean that 68% (1 standard deviation) of my values fall in the range of 10-7.5 = 2.5 months to 10+7.5 = 17.5 months?
That “feels” about right but math is not about “feels”, I am looking for the actual explanation so I don’t get shot down by someone who actually knows and can explain these numbers correctly.
Goal is to get beyond just telling our “customers” (other internal departments) “it takes an average of 10 months for us to complete projects” to a more accurate and defendable data driven statement that says “depending on a few variables, we typically deliver most projects in 2.5 to 17.5 months”. That sets more realistic expectations up front and immediately opens the door to the discussion regarding which variables cause it to be shorter or longer than the “10 month average” the Team had been quoting.
So is my usage of standard deviation above correct?
Thanks for any feedback!
I have been analyzing the project-related data from the work accomplished by the one-man army over the last two years.
I have been tasked by our VP with adding Standard Deviation to the report that I have developed to show what has been accomplished over the last 2.5 years and what we can accomplish with our new resources once they come up to speed.
I have not had to do Standard Deviation stuff since Statistics class back in college in the late 70’s. Never was called on to use it in 48 years of my IT career…until now. I feel like I have forgotten what little I ever knew about it!
To refresh my memory, I have read various things on the Internet about what it is and does but want to make sure I am properly interpreting what I think it says.
I have the data extracted to Microsoft Excel and I am using its Std Dev function and it gives me what looks like a reasonable answer. Std Dev is used in conjunction with the Average / Mean which I also have and what the report was originally providing.
There are 305 rows of data regarding projects since January 2020. The relevant numbers are the number of Months from beginning to end it took to complete each project. This number varies greatly depending on project complexity and delays due to dependencies on 3rd parties to do some of the work.
According to Excel my Average/Mean is 10 months and my Standard Deviation is 7.5 months.
My Range of values is from .1 month to 25.1 months.
So based on the 68-95-99.7 rule for 1, 2 and 3 standard deviations, does this mean that 68% (1 standard deviation) of my values fall in the range of 10-7.5 = 2.5 months to 10+7.5 = 17.5 months?
That “feels” about right but math is not about “feels”, I am looking for the actual explanation so I don’t get shot down by someone who actually knows and can explain these numbers correctly.
Goal is to get beyond just telling our “customers” (other internal departments) “it takes an average of 10 months for us to complete projects” to a more accurate and defendable data driven statement that says “depending on a few variables, we typically deliver most projects in 2.5 to 17.5 months”. That sets more realistic expectations up front and immediately opens the door to the discussion regarding which variables cause it to be shorter or longer than the “10 month average” the Team had been quoting.
So is my usage of standard deviation above correct?
Thanks for any feedback!


")